
Synthetic Data Generation Market Growth, Industry Analysis, 2026-2034
REPORT DETAILS
Synthetic Data Generation Market Summary
The synthetic data generation market size was valued at USD 279.74 million in 2025, growing at a CAGR of 34.87% during 2026–2034. Expansion of artificial intelligence coupled with geopolitical risk and cybersecurity threats are boosting the growth of the market.
Market Statistics
Key Takeaways
- North America dominated the synthetic data generation market in 2025 and held around 43.0% share. High AI investment and use of synthetic datasets supported the market growth.
- Asia Pacific is expected to grow at the fastest CAGR of 41.2% during 2026–2034. Growth is driven by smart city projects and digital infrastructure development.
- The solution/platform segment contributed for around 65.0% share in 2025. More firms are using synthetic data platforms for AI model training and analytics.
- The services segment is expected to grow with a CAGR of 36.5% during the forecast period 2026-2034. The demand for consulting, integration, and support services is increasing.
- The tabular data segment held around 40.0% market share in 2025. The segment is widely used in banking, retail, and healthcare industries.
- The healthcare & life sciences segment is expected to grow at the fastest CAGR of 38.8% during the forecast period. Rising use of AI in diagnostics and drug research is supporting the segment growth.
*Note: Figures and projections outlined in this report are the result of Polaris Market Research’s proprietary analytical processes, grounded in the latest available datasets and market observations.
Industry Dynamics
- Rising AI use is increasing demand for synthetic datasets for training, testing, and improving AI model performance.
- More cyberattacks are pushing companies to use synthetic data for secure analytics and safer AI system development.
- Strict data privacy regulations are propelling synthetic data adoption for compliance, secure sharing and business operations worldwide.
- High setup costs are preventing small businesses worldwide from adopting synthetic data.
AI Impact on Synthetic Data Generation Market
- AI adoption is increasing synthetic dataset demand across multiple business industries.
- Synthetic data improves AI model accuracy with balanced training data environments.
- Companies use synthetic datasets for testing, validation, and faster business deployment globally.
- Fraud detection and medical imaging applications are increasing synthetic data usage worldwide.
What is Synthetic Data Generation?
Synthetic data generation involves creating artificial datasets that replicate the statistical properties and patterns of real-world information. These datasets are used for model development, software testing, simulation environments, or algorithm validation, without exposing sensitive or personally identifiable information. The ability to control variables, balance rare events, and simulate future scenarios made synthetic data a valuable asset for industries such as finance, healthcare, automotive, cybersecurity, and retail. Companies are adopting synthetic datasets to accelerate innovation cycles while complying with regulations such as GDPR, HIPAA, and other data governance frameworks.
To Understand More About this Research: Download Sample Report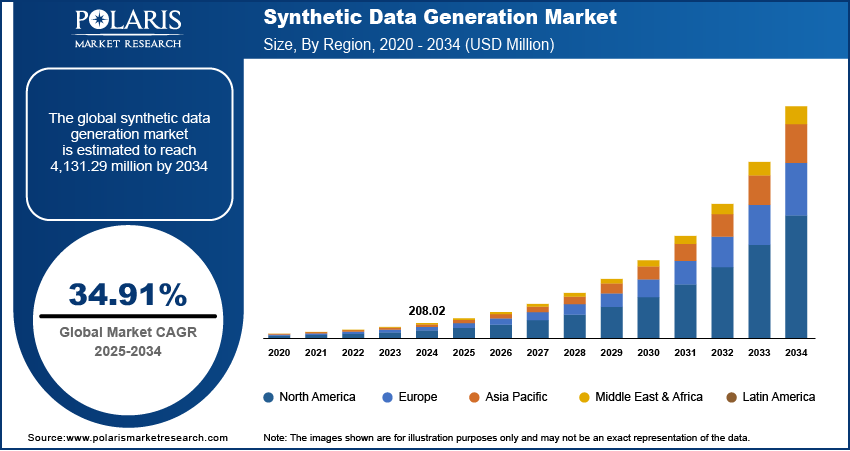
Source: Polaris Market Research Analysis
The financial services sector is leveraging synthetic data to simulate customer transactions and fraud scenarios, enhancing the training of fraud detection models without risking customer confidentiality. In healthcare, synthetic datasets allow developers to build AI applications for diagnostics and treatment planning without accessing real patient records. Additionally, autonomous vehicle developers use synthetic traffic environments to model rare driving events, improving vehicle safety systems without relying entirely on costly real-world data collection.
The rapidly evolving global regulatory landscape related to personal data usage is accelerating the growth of the synthetic data generation market. Regulation such as the General Data Protection Regulation (GDPR) in the European Union and the California Consumer Privacy Act (CCPA) in the US mandates strict compliance for organizations handling user data. For instance, a company failing to comply with severe GDPR violations, faces fines reaching up to USD 21.8 million or 4% of its total global turnover from the previous fiscal year, whichever amount is higher. Additionally, several countries in Asia-Pacific and Latin America introduced national privacy frameworks requiring data localization and user consent. These regulations are making it increasingly difficult for enterprises to access large-scale real data for training machine learning and AI systems without risking non-compliance or penalties. Synthetic data provides anonymous dataset generation that replicate the statistical characteristics of real-world data without containing any personally identifiable information.
Furthermore, surging digital transformation across industries is increasing the demand for high-volume, well-labeled, and diverse datasets in sectors such as healthcare, automotive, retail, and financial services. AI and machine learning are becoming integral to business functions such as personalized marketing and automated diagnostics, pushing organizations to seek training data that captures diverse scenarios and user behaviors. However, collecting, cleaning, and labeling real-world data is time-consuming, expensive, and limited by availability. Synthetic data provides a flexible alternative by allowing enterprises to generate custom datasets that match use-case requirements without relying on extensive real-world sampling.
How Synthetic Data Generation Works
The synthetic data generation process starts with existing datasets. The system analyzes data patterns and examines how values link with each other. Then, tools like GANs and VAEs create fresh data samples with same patterns. The new data is not copied from real records. After generating new data it is checked again to match real-world patterns and quality levels.
Industry Dynamics
Expansion of Artificial Intelligence Driving Scalable Data Generation Needs
The rapid growth of artificial intelligence adoption across global industries is increasing the need for diverse, high-volume datasets to support model development, validation, and deployment. According to a report from the United Nations Conference on Trade and Development (UNCTAD), the global AI market is estimated to reach USD 4.8 trillion by 2033, reflecting a 25-fold increase over a decade. This exponential growth highlights the scale of AI integration into business operations, product development, and decision-making workflows. Privacy constraints, high costs, and limited access to real-world data are pushing the adoption of synthetic data as a scalable alternative for training complex models.
Synthetic data allows developers to simulate real-world conditions, balance rare classes, and introduce controlled variations to improve model accuracy. Also, it supports continuous testing and tuning, in dynamic environments where real-time data collection are not feasible. Enterprises using AI for fraud detection, autonomous navigation, or medical image analysis are leveraging synthetic data to expand model capabilities while reducing dependence on actual user data. This approach accelerates time-to-deployment ensuring that data constraints do not hinder algorithm development at scale.
Geopolitical Risk and Cybersecurity Threats
Increasing global concerns around data sovereignty and cybersecurity are further boosting the market growth. According to the FBI’s Internet Crime Report 2024, the agency received 859,532 cybercrime complaints in the US, with reported losses totaling USD 16.6 million, a significant rise from USD 12.5 million in 2023. The rise in cyber incidents, coupled with growing geopolitical uncertainty, is leading to tighter regulatory frameworks around cross-border data transfers, data localization, and national security requirements. These developments are creating operational barriers for multinational organizations that rely on global data exchange for AI system development.
Synthetic data navigate these restrictions by enabling companies to build usable datasets that does not contain real or sensitive information. This capability helps reduce exposure to compliance violations while maintaining continuity in AI workflows across borders. Organizations in sectors such as defense, banking, and energy are increasingly investing in synthetic data platforms to mitigate risks associated with breach-prone or politically sensitive datasets. The growing need for secure, localized, and regulation-friendly alternatives is highlighting synthetic data’s role as a strategic asset in enterprise data governance planning.
To Understand More About this Research: Download Sample Report
Source: Polaris Market Research Analysis
Synthetic Data vs Real Data
| Parameter | Synthetic Data | Real Data |
| Source | Made from existing data patterns | Taken from real users and activities |
| Privacy | Lower privacy risks | May include sensitive information |
| Scalability | Can be created quickly in large amounts | Needs more time for collection |
| Accuracy | Good for testing and training | Shows actual real-world behavior |
| Limitations | May miss rare situations | Includes real conditions and events |
| Usage | Used for testing and analytics | Used in daily business operations |
Source: Polaris Market Research Analysis
Synthetic Data Limitations
Synthetic data may not always reflect real-world scenarios and unexpected circumstances. Some time, the generated data may reproduce errors or bias present in the original datasets. The quality of the data also relies on the original dataset used in the generation process. Final result and overall performance is influenced by the quality of the input data.
Segmental Insights
Offering Analysis
The segmentation, based on offering includes, solution/platform and services. The solution/platform segment accounted for 65.0% in 2025. This is attributed to the rising deployment of synthetic data generation tools across industries for AI training, data simulation, and privacy-preserving analytics. Enterprises are increasingly investing in dedicated platforms that offer scalable, automated data synthesis capabilities, enabling them to generate structured and unstructured data on demand. These solutions help address challenges related to limited or biased training datasets and offer compatibility with various AI/ML pipelines for technology providers and research institutions.
The services segment is expected to grow at the fastest CAGR of 36.5% during the forecast period due to rising demand for consultation, customization, and integration of synthetic data frameworks into existing enterprise infrastructure. Businesses across healthcare, retail, and BFSI are adopting synthetic data to address specific operational and regulatory needs. Vendors offering managed services, implementation support, and compliance-driven solutions are witnessing increased demand, as enterprises are adopting synthetic data to meet evolving regulatory and operational requirements.
Data Type Analysis
The segmentation, based on data type includes, tabular data, text data, image and video data, and others. The tabular data segment dominated the market valued at 40.0%, in 2025, driven by rising adoption in sectors such as banking, insurance, retail, and healthcare. For instance, in May 2025, HDR UK Midlands launched Helix, an open‑source AI/ML framework for tabular data analysis, built for structured datasets across scientific and engineering domains. Helix integrated synthetic data, bias detection, and explainable AI to enable transparent machine learning on tabular data in healthcare and life sciences. Structured datasets are essential for use cases such as risk modeling, customer profiling, fraud detection, and supply chain analysis. Companies are increasingly generating synthetic tabular data to simulate transaction logs, patient records, and financial statements, maintaining statistical accuracy and ensuring privacy compliance.
The image and video data segment is projected to register the highest growth rate of 40.4% over the forecast period. The growth is fueled by its expanding use in computer vision applications, including autonomous driving, facial recognition, and medical imaging. For example, in April 2025, Endava partnered with SideFX to integrate Houdini’s procedural animation software with Endava’s synthetic data generation tools, enabling the production of pixel-perfect datasets for computer vision training. Developers of vision-based AI systems are using synthetic images and video sequences to train algorithms in controlled virtual environments. Through this data set organizations are able to reduce the cost of manual annotation and expand the availability of rare visual data scenarios.
Application Analysis
The segmentation, based on application includes, AI/ML training and development, test data management, data analytics and visualization, enterprise data sharing, and others. The AI/ML training and development segment dominated the market, valued at 39.0% in 2025. This dominance is attributed to the rising prioritization of model accuracy, generalizability, and robustness by enterprises. Synthetic data is used to simulate edge cases and increase dataset diversity, improving performance across a variety of AI models. This application is important in fields such as predictive analytics, NLP, and anomaly detection, where limited or unbalanced training data results in model bias or underperformance.
The enterprise data sharing segment is expected to grow at the fastest pace at a CAGR of 38.9% during the forecast period, due to increasing collaboration across departments, subsidiaries, and partners in data-driven businesses. For instance, in November 2024, SAS acquired Hazy’s synthetic data software assets to enhance its SAS Data Maker and Viya platforms, providing enterprise-grade tools for privacy-preserving data generation. Synthetic datasets enable safe sharing of business-critical data without revealing proprietary or sensitive customer information. Organizations are using this approach to maintain data agility across cloud platforms, analytics teams, and third-party vendors while complying with data protection standards.
Industry Vertical Analysis
The segmentation, based on industry vertical includes, BFSI, healthcare & life sciences, retail & e-commerce, automotive & transportation, government & defense, IT and ITeS, manufacturing, and other verticals. The BFSI segment dominated the market accounting for 22.0%, in 2025. This dominance is attributed to the growing need for secure data handling in fraud analytics, credit scoring, and regulatory compliance. Financial institutions are adopting synthetic data to train risk models, test cybersecurity systems, and simulate transaction data without exposing real customer identities. For example, in October 2024, Infosys Finacle launched the Finacle Data & AI Suite, featuring an automated data pipeline, modular lakehouse, and a patent-pending synthetic data generation feature designed for privacy-safe AI training in banks. The sector’s strong focus on data security and privacy further fuels the market growth.
The healthcare and life sciences segment is anticipated to expand at the highest CAGR of 38.2% through 2034. The need to train AI models for diagnostics, patient monitoring, and drug discovery led to growing interest in synthetic clinical data, medical images, and genomic sequences. Stringent privacy regulations are limiting access to real patient data, pushing healthcare providers and researchers to adopt synthetic data for compliance with HIPAA and similar standards.
To Understand More About this Research: Request Customization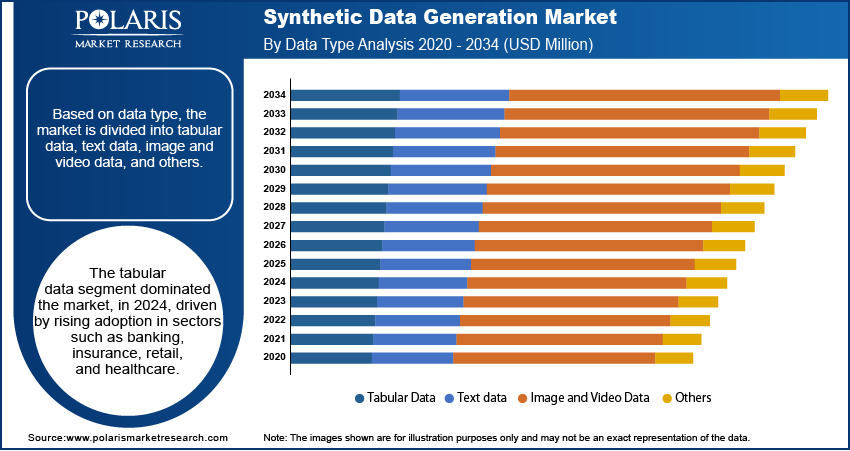
Source: Polaris Market Research Analysis
Regional Analysis
North America synthetic data generation market accounted for largest global market share capturing 43.0% in 2025, driven by federal and state-level initiatives aimed at accelerating AI development. Programs under the CHIPS and Science Act increased R&D spending for AI and related technologies, boosting the adoption of synthetic datasets as safer alternatives to real-world data. Also, the increasing adoption of synthetic data to address cybersecurity threats and data sovereignty concerns is further fueling the market growth. Enterprises are using synthetic datasets to train and validate models without transferring personal or operational data across borders. Localizing model training through synthetic datasets allows organizations to meet compliance requirements while maintaining innovation and model precision.
The US Synthetic Data Generation Market Insight
The US, in particular, dominated the regional market share in 2024. This growth is attributed to the developed AI ecosystem coupled with rising investment from companies such as Microsoft, IBM, NVIDIA, and Google. For example, in April 2025, NVIDIA announced plans to produce up to USD 500 million worth of AI servers in the US over the next four years, in partnership with manufacturers such as TSMC, Foxconn, Wistron, Amkor, and SPIL. These investments are significantly increasing the demand for scalable, high-quality training datasets. Organizations are integrating synthetic data into operations to reduce bias, simulate edge cases, and accelerate safe AI deployment across enterprise environments. In addition, US academic and government institutions are advancing synthetic data research, thus propelling the growth of the market. The growing importance of edge AI, cybersecurity resilience, and digital twins in government-led innovation projects further fuels synthetic data adoption in the region.
Asia Pacific Synthetic Data Generation Market
The Asia Pacific synthetic data generation market is projected to witness fastest growth at a CAGR of 41.2% during the forecast period. This is attributed to the growing regional investments in digital governance and smart city infrastructure. In August 2024, the Government of India approved 12 new industrial smart city projects with a total cost of approximately USD 3.4 million, to develop trunk infrastructure packages. These initiatives are increasing the demand for AI tools that require large, secure datasets. Synthetic data are adopted across civic services, transportation networks, and energy systems to safeguard citizen information enabling advanced analytics and automation.
Additionally, the rapid shift toward AI in regulated sectors such as healthcare and finance is further accelerating the market growth in the region. Countries such as Japan, China, and Australia are using AI to improve medical diagnostics, fraud detection, and financial forecasting. However, limited access to real data due to privacy laws and operational constraints led to greater reliance on synthetic datasets. These datasets help institutions meet data-sharing requirements and support AI model development without compromising patient confidentiality.
Europe In Synthetic Data Generation Market Overview
The Europe synthetic data generation market is projected to reach significant revenue share valued at 24.0% by 2034, owing to the strict data protection laws in the region. The General Data Protection Regulation (GDPR) remains a key framework governing the use of personal data in AI training environments. For instance, in April 2024, the European Union strengthened this regulatory environment by aligning the EU AI Act with the GDPR, ensuring comprehensive protection of individual rights in AI systems using personal data. Therefore, to address these regulatory constraints, organizations are increasingly adopting synthetic data to generate anonymized, risk-free datasets.
In addition, rising public sector investment in AI advancement is further accelerating the market growth in the region. Several initiatives such as Horizon Europe and the Digital Europe Programme are funding projects that explore privacy-preserving AI solutions. These programs are supporting collaborative research across member states, universities, and technology firms to enhance responsible AI practices. The EU’s leadership in global discussions on ethical AI is boosting the demand for synthetic data as a compliant and innovation-friendly solution across the region.
To Understand More About this Research: Request Customization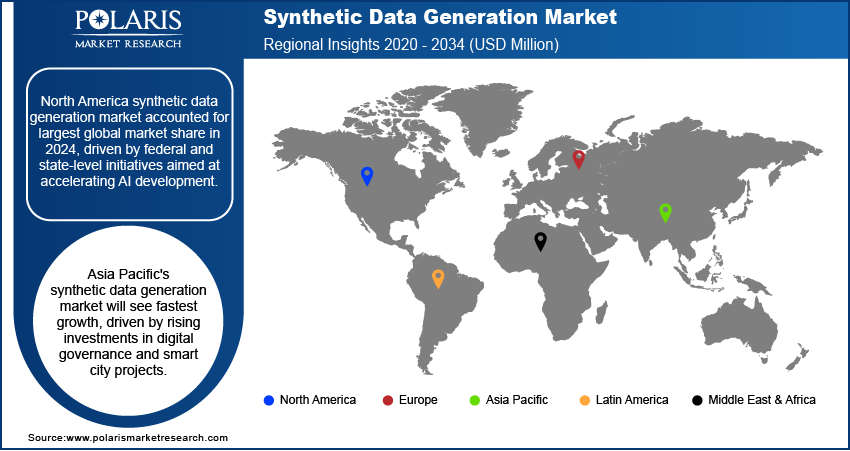
Source: Polaris Market Research Analysis
Key Players & Competitive Analysis Report
The synthetic data generation market is becoming increasingly competitive, driven by rapid advancements in AI, data privacy regulations, and demand for secure model training environments. Leading technology firms and emerging AI startups are actively developing solutions that generate high-quality, diverse datasets while minimizing privacy risks. These companies are focusing on enhancing platform capabilities by integrating generative AI models, automated data labeling, and privacy assurance mechanisms. Strategic investments in R&D and cloud-native deployment are helping vendors improve scalability and meet growing enterprise demand for synthetic data across sectors such as finance, healthcare, automotive, and retail. The market’s competitive dynamics are further influenced by strategic collaborations, acquisitions, and funding rounds aimed at strengthening data-centric AI capabilities.
Prominent companies in the synthetic data generation market include Amazon Web Services, Inc., Databricks, Inc., Facteus, Inc., Google LLC, Gretel Labs, Inc. (Gretel.ai), Hazy Limited, IBM Corporation, Informatica Inc., Microsoft Corporation, MOSTLY AI Solutions MP GmbH, NVIDIA Corporation, OpenAI, Inc., Sogeti (Capgemini SE), Synthesis AI, Inc., and Tonic AI, Inc.
Key Players
- Amazon Web Services, Inc.
- Databricks, Inc.
- Facteus, Inc.
- Google LLC
- Gretel Labs, Inc. (Gretel.ai)
- Hazy Limited
- IBM Corporation
- Informatica Inc.
- Microsoft Corporation
- MOSTLY AI Solutions MP GmbH
- NVIDIA Corporation
- OpenAI, Inc.
- Sogeti (Capgemini SE)
- Synthesis AI, Inc.
- Tonic AI, Inc.
Future Outlook
The synthetic data generation market is expected to grow steadily in coming years. Rising use of digital technologies is increasing demand for scalable datasets across industries. Rising data deficits and strict privacy regulations are also fueling the growth of the market. Businesses are installing secure and affordable data solutions for testing and analytics. Faster and higher quality datasets are empowering businesses with the support of advances in generative technologies.
Industry Developments
- January 2026: K2view released new synthetic data generation solutions for privacy-safe enterprise datasets. (Source: k2view.com)
- March 2025: SmartOne AI launched a suite of tools designed to generate high-fidelity synthetic data for AI applications, with a focus on time-series and IoT sensor streams. This offering enabled organizations to train and validate AI models using realistic, privacy-compliant datasets across industrial and smart infrastructure sectors. (Source: prnewswire.com)
- October 2024: GE HealthCare led the SYNTHIA consortium, which included partners such as Pfizer and Novo Nordisk, to develop standardized synthetic healthcare data frameworks supporting AI algorithm development for diseases such as cancer and diabetes. This effort strengthened synthetic data adoption by creating validated tools and methods for privacy-preserving healthcare AI innovation. (Source: signapulse.gehealthcare.com)
- May 2024: South Korea’s Personal Information Protection Commission (PIPC) released official reference models and usage guidelines for generating synthetic data across formats including images and sensor data. This regulatory initiative promoted safe and effective deployment of synthetic data for machine learning and AI, contributing to greater trust and adoption in public and enterprise sectors. (Source: digitalpolicyalert.com)
Market Segmentation
By Offering Outlook (Revenue, USD Million, 2021–2034)
- Solution/Platform
- Services
By Data Type Outlook (Revenue, USD Million, 2021–2034)
- Tabular Data
- Text data
- Image and Video Data
- Others
By Application Outlook (Revenue, USD Million, 2021–2034)
- AI/ML Training and Development
- Test Data Management
- Data analytics and visualization
- Enterprise Data Sharing
- Others
By Industry Vertical Outlook (Revenue, USD Million, 2021–2034)
- BFSI
- Healthcare & Life sciences
- Retail & E-commerce
- Automotive & Transportation
- Government & Defense
- IT and ITeS
- Manufacturing
- Other Verticals
By Regional Outlook (Revenue, USD Million, 2021–2034)
- North America
- US
- Canada
- Europe
- Germany
- France
- UK
- Italy
- Spain
- Netherlands
- Russia
- Rest of Europe
- Asia Pacific
- China
- Japan
- India
- Malaysia
- South Korea
- Indonesia
- Australia
- Vietnam
- Rest of Asia Pacific
- Middle East & Africa
- Saudi Arabia
- UAE
- Israel
- South Africa
- Rest of Middle East & Africa
- Latin America
- Mexico
- Brazil
- Argentina
- Rest of Latin America
Market Report Scope
| Report Attributes | Details |
| Market Size in 2025 | USD 279.74 Million |
| Market Size in 2026 | USD 376.25 Million |
| Revenue Forecast by 2034 | USD 4,130.23 Million |
| CAGR | 34.87% from 2026 to 2034 |
| Base Year | 2025 |
| Historical Data | 2021–2024 |
| Forecast Period | 2026–2034 |
| Quantitative Units | Revenue in USD Million and CAGR from 2026 to 2034 |
| Report Coverage | Revenue Forecast, Competitive Landscape, Growth Factors, and Industry Trends |
| Segments Covered |
|
| Regional Scope |
|
| Competitive Landscape |
|
| Report Format |
|
| Customization | Report customization as per your requirements with respect to countries, regions, and segmentation. |
Source: Polaris Market Research Analysis
FAQ's
The global market size was valued at USD 279.74 million in 2025 and is projected to grow to USD 4,130.23 million by 2034.
The global market is projected to register a CAGR of 34.87% during the forecast period.
• North America dominated the synthetic data generation market in 2025 and held around 43.0% share.
A few of the key players in the market are Amazon Web Services, Inc., Databricks, Inc., Facteus, Inc., Google LLC, Gretel Labs, Inc. (Gretel.ai), Hazy Limited, IBM Corporation, Informatica Inc., Microsoft Corporation, MOSTLY AI Solutions MP GmbH, NVIDIA Corporation, OpenAI, Inc., Sogeti (Capgemini SE), Synthesis AI, Inc., and Tonic AI, Inc.
• The tabular data segment held around 40.0% market share in 2025.
The enterprise data sharing segment is expected to grow at the fastest pace at a CAGR of 38.9% during the forecast period
Download Sample Report of Synthetic Data Generation Market
Please fill out the form to request a customized copy of the research report.
